

Last summer, AI ‘godfather’ Yann LeCun wrote that large language models (LLMs) are an “off ramp on the road to human-level AI”.

This echoes Gary Marcus’ 2022 essay Deep Learning Is Hitting a Wall—although LeCun and Marcus disagree on details of the challenges. And such warnings are apparently being borne out: OpenAI’s latest GPT-4.5 LLM performs worse on leading benchmarks than some older models, at a much higher price. Tech journalist Ed Zitron recently wrote an evidence-based polemic about why the LLM market is unsustainable.
On the other hand, OpenAI presents GPT-4.5 as a model with improved human-like fluency (which it seems to be, although this is challenging to measure with precision), rather than a model using ‘reasoning’ to perform well on technical benchmarks (like OpenAI’s o1, Anthropic’s Claude 3.7 Sonnet or DeepSeek R1). With (carefully phrased) optimism, Sam Altman blogged early this year that “We are now confident we know how to build AGI as we have traditionally understood it”, and New York Times journalist Ezra Klein seems to be convinced.
So what’s going on here? Is the future of AI bright or not? Are LLMs a dead end or a platform for AGI?
In short, the problems of LLMs are real and likely to be persistent, while the future of AI is extremely bright. This blog explains why LLM problems are inevitable—in terms of dimensionality. The problem of dimensionality is that the world is far too complex, and the data that are available about the world (although extensive) far too limited, for LLMs alone to deliver flexible intelligence. While the increasing size of LLMs in terms of parameter count and training data is continually trumpeted in research and the media, the dimensionality implications of this increasing size receive little attention. This is an important oversight.
I explain below how three types of dimensionality—of data, models and the world—have unavoidable effects on LLMs. Then, from the same perspective of dimensionality, I offer views on promising future directions for AI.
Ultimately, the path of dimensionality leads to the same conclusion as my recent blogs that successful AI “requires a detailed focus on local conditions”. However, my reasoning here is significantly more technical. I’ll aim to take you through it in a clear and understandable way (with technical detail in footnotes1).
Black boxes or plausibility monsters
Before looking at dimensionality, let’s take a look at what LLMs are.
It is common to refer to LLMs as ‘black boxes’, implying that we don’t understand why they produce the outputs that we see from them.
But the black box metaphor is misleading. In fact, we know very well what LLMs are doing. After all, they were built by humans. We understand the operation of LLMs much, much better than we understand the human brain.
Very simply, here’s what LLMs are and do. They pattern match between examples in their massive training data and the prompts with which they are presented, combining the most relevant-seeming examples into each response.
In somewhat more detailed terms:
LLMs are software representations of highly complex mathematical functions, which can ‘learn’ how languages and other information schemes work. Such schemes include human languages in text and audio, computer code, and visual information like images and video (which are converted into formats that LLMs can process).
During the process of LLM ‘training’, a large amount of data about the world (books, articles, blogs, online posts, computer code, etc.) is used to progressively align LLM responses with the apparent ‘ground truth’ represented by the data. This involves iterative adjustment to the ‘weights’ in the LLM’s mathematical function that determine which data have influence on the output.
When an LLM is used (known as ‘inference’), it takes user input (known as a ‘prompt’, which may be quite lengthy—e.g. an entire book or more) and generates an output, one ‘token’ at a time. A token is analogous to a word, but somewhat more compact.2 In a textual exchange, an LLM chooses the ‘best’ response (usually the one that appears most likely from the data3), one word at a time.
This pattern matching is fantastically complex at the scale of modern LLMs (more on that in the next section)—which is the main reason that LLMs are viewed as ‘black boxes’. There are emerging efforts to understand LLM processes, known as ‘mechanistic interpretability’—a bit like psychology for LLMs (Anthropic’s leading paper is Mapping the Mind of a Large Language Model)—but the efforts are in early days.
Some have trivialized pattern matching by LLMs, such as (memorably) the 2021 Google paper On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?, which focused on the dangers of LLMs.4 In fact, LLMs do pattern matching extremely well—better all the time as new models are introduced. This amazing ability burst into the public consciousness with the launch of ChatGPT in 20225, which arguably was evidence of Arthur C. Clarke’s adage that “Any sufficiently advanced technology is indistinguishable from magic.”
So rather than ‘stochastic parrots’, my preferred nickname for LLMs is ‘plausibility monsters’6. This captures LLMs’ amazing capabilities and poorly-understood risks, especially in the uncertain territory of things that are plausible but incorrect:

LLMs are almost always plausible—because plausibility is what prediction of the most-likely next word through pattern matching is designed to produce—but they are frequently not correct. So although LLMs are getting steadily better at identifying and communicating knowledge, they continue to spend too much time in the danger zone, often in the form of ‘hallucinations’ (essentially made-up facts), but with increasing evidence that LLMs will also engage in ‘deception’.
This is a problem that is not going to go away. To explain why that’s the case, let’s turn to dimensionality.
Three types of dimensionality
We must consider three types/levels of dimensionality: data dimensionality, model dimensionality and world dimensionality7. Each of these involve big numbers, but they are big numbers at radically different scales.
Data dimensionality refers to the amount of available LLM training data that is available to provide LLMs with examples of how things happen in the world. The state of play on this was summarized by Azeem Azhar in an excellent blog last year AI’s $100bn question: The scaling ceiling. The estimated stock of human-generated textual data in 2025 is between about 1014 and 1015 tokens, possibly extending towards about 1016 (10 quadrillion) tokens by around the 2040s. Assuming that each token requires about 3-4 bytes of storage, a reasonable upper bound on the amount of data available to train LLMs is around 1016-1017 bytes.8
That’s a lot of data, but, as Azeem explained, current estimates are that LLM training will exhaust this data supply by around 2030. There are no easy ways to deal with this shortage. Azeem mentions ‘undertraining’—i.e. increasing the number of model parameters without increasing training data size—but this is not a long-term solution, and runs into the model dimensionality challenges that I describe below. Some have suggested training on ‘synthetic data’ generated by AI models, but there is research indicating an eventual likelihood of model collapse from training on synthetic data, due to iterative amplification of error and bias in the data.
This problem of data inadequacy is large, even on its own. But it becomes even starker when we move to the next layer of dimensionality.
Model dimensionality is associated with the number of ‘parameters’ in an LLM. A parameter represents a notional characteristic of the world. To take a simple example, the parameters of an automobile might include make, model, engine size, interior color, etc.
LLMs have a lot of parameters (also known as ‘features’), because the world has a lot of characteristics9. It is estimated that OpenAI’s new GPT-4.5 model may have 5-7 trillion parameters. Each parameter of an LLM is typically represented by between 1 byte (8-bit integer) and 4 bytes (32-bit float). Taking the midpoint of each of these ranges, a reasonable calculation of the number of different states (also known as the ‘feature space’) that could be represented by GPT-4.5 is:
or about 1028,900,000,000,000 states.
That is a very, very, very big number, and it is not hard to see that it is much, much bigger than our estimated upper bound on training data of 1016-1017 bytes: approximately 28,900,000,000,000 orders of magnitude bigger (since the 16-17 orders of magnitude in the first estimate get lost in rounding). This is like the famous parable of the king and the chessboard, on really powerful steroids.
This means that almost all of the feature space of a modern LLM is empty. There is nowhere near enough data to encode meaning into such an enormous space. Before exploring what this emptiness means in the next section, let’s turn to the third type of dimensionality.
World dimensionality is about the dimensionality of the whole world. For this, I will not attempt a specific numerical estimate. Rather, I will demonstrate that the difference of scale between model and world dimensionality is at least as great as that between data and model dimensionality.
Let’s say you have a modest collection of 50 books on your shelf at home. The number of ways that you could organize those books is 50! (read ‘fifty factorial’).10 50! equals 30,414,093,201,713,378,043,612,608,166,064,768,844,377,641,568,960,512,000,000,000,000 or about 3 x 1064—48 orders of magnitude bigger than the total number of bytes of data in the world that we calculated above.11
Now let’s extrapolate to all the other stuff there is in the world. There are about 1.3 x 1050 atoms in the Earth, which means that the number of ways that you could arrange them in a straight line (if that were possible) is (1.3 x 1050)!12 (And there are lots more ways to arrange them in three-dimensional space, subject to the laws of physics and chemistry.) That number is much, much larger than the scale we calculated for model dimensionality, multiplied times itself—i.e. (1028,900,000,000,000)2__indicating that the model/world scale differential is much larger than the data/model scale differential. And this doesn’t take account of the fact we might want to think about the dimensionality of the whole universe (which has about 1082 atoms) or that each atom has a very large number of quantum states.
Of course, many of these states of the world/universe are extremely similar. The world in which The Great Gatsby is on my shelf to the left of Understanding Media isn’t very different from the one where they are reversed. However, notoriously, infinitesimal differences in initial conditions can be surprisingly important over time.
In any event, the key point is about difference of scale.
Comparing these unimaginably huge numbers to a scale that is possible to illustrate, consider the 1977 educational film Powers of Ten created by Charles and Ray Eames. It zooms from a couple picnicking on the shore of Lake Michigan up to a width of 100 million light years (1024 meters)—beyond the scale of galactic clusters—and then back down into the man’s hand to 10−16 meters—less than the width of a proton. This difference of 40 orders of magnitude is much greater than our first calculation above of data dimensionality, but in no way comparable to the titanically greater orders of magnitude of model dimensionality, let alone world dimensionality.
The curse of dimensionality and LLMs
The term ‘curse of dimensionality’ was coined in 1957 by Richard E. Bellman to describe the computational challenges of using high-dimensional data in dynamic programming. Specifically, the curse is associated with the fact that data sparsity increases as dimensionality increases, because of the relative lack of data to fill the larger space. Sparsity is the phenomenon, mentioned above, that most of the feature space of an LLM is empty, because of the large difference between data and model dimensionality.
The curse of dimensionality is a significant problem in machine learning, and appears to be a major reason that the behavior of LLMs is unpredictable. For example, a late 2024 paper The structure of the token space for large language models examined the structure of feature space13 of GPT2, LLEMMA7B and MISTRAL7B (three LLMs with significantly lower dimensionality than more recent ones like GPT-4.5), and concluded that information is highly concentrated in certain areas of the space, producing
abrupt changes in dimension [which] imply that the behavior of the large language model as a whole is unstable to small perturbations. … This instability will likely preclude strong guarantees about the model’s generative performance without intimate knowledge of how the token subspace is embedded within the ambient latent space.
This problem of instability is closely tied to the problems of hallucinations and deception that are described above. The dimensionality discrepancy between the feature space (very big) and data (much smaller) makes the instability essentially unavoidable. Another consequence of the unpredictability of a large, mostly vacant feature space is that LLMs are vulnerable to attack through use of specially-crafted prompts aimed at areas of the feature space that are not well-populated by data.14
The overall problem of dimensionality and the current path of ever-larger LLMs can be summarized as follows: By continually building bigger LLMs (i.e. with higher model dimensionality) in an effort for those models to better represent the world (and its huge dimensionality), model developers are creating mostly-vacant data structures that are increasingly unpopulated (given the limits of data dimensionality) and unstable.
Put differently, there is an inherent tension in the growth of LLMs:

I asked Google’s Imagen 3 model to produce a pictorial illustration of this tension with the following prompt: “Please draw a simple picture of a man (ideally something like a stick figure) trying to position a high-dimensional machine learning model between the extremes of high-dimensional data and the much, much higher dimensional world.” Here’s what I got:
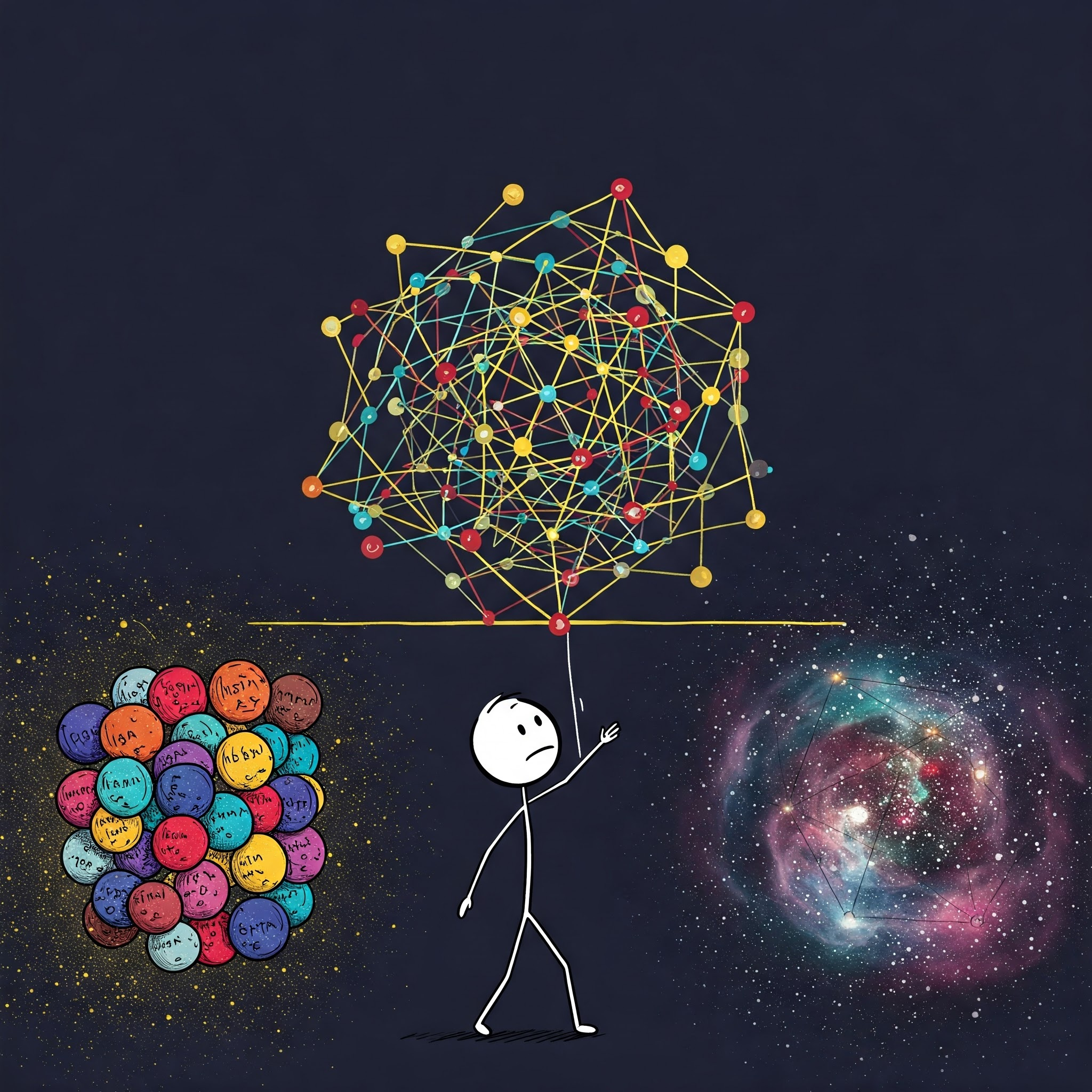
It is a difficult choice indeed for this sad-looking LLM operator to continue walking away from limited data, on a quest for universal-scale dimensionality. Does he look like Sam Altman?
This tension offers clear support for the approach of designing smaller-dimensional LLMs. For example, Alibaba recently released QwQ-32B, an open source, 32 billion parameter reasoning model with leading or strong performance on multiple benchmarks. Initial attention to the benefits of smaller models has focused on efficiency and ability to run on smaller devices, but increased reliability (particularly when trained in specific domains) is also an emerging benefit, and one that appears to be linked to the curse of dimensionality. It remains to be seen whether the smaller model approach can rescue LLMs from the curse of dimensionality—my view is, not entirely—but the approach is promising.
In sum, the curse of dimensionality is one to be feared for LLMs. But, fortunately (and apart from the smaller model approach), this cloud has a silver lining.
Manifolds, the blessing of dimensionality and focus
The silver lining of dimensionality relates to the idea of a ‘manifold’, which is mathematical concept of a space (in 1 or more dimensions) that resembles normal (Euclidean) space at all points. That is, manifolds are smooth, continuous structures: every object in the world has the form of a 3-dimensional manifold. In contrast, spaces that are not manifolds have discontinuities—but these do not exist in the real world.
The feature space of an LLM is not a real-world structure, and it is not itself a manifold, because of the discontinuities resulting from the emptiness of most of its feature space. However, the ‘manifold hypothesis’, developed over the past two decades, suggests that data in high-dimensional structures (like an LLM feature space) concentrate in low-dimensional manifolds within the high-dimensional space. Recent research (including the ‘token space’ paper discussed in the previous section) has made this more precise, indicating that LLM feature spaces are ‘stratified manifolds’, meaning that multiple manifolds of dense data exist within the feature space.
For example, taking the automobile example used above, there might be a region/manifold within an LLM feature space that contains everything known about the automotive industry. The rest of the feature space might be irrelevant to automobiles, and indeed likely to confuse responses when the LLM encounters automobile-related prompts.
Put differently, LLMs contain clusters of relatively well-organized data, but discontinuities between these clusters (which are an inevitable consequence of dimensionality) disrupt the overall performance of the LLM as a system. An analogy might be a country of isolated villages, with poor communications among the villages making national governance ineffective.
The silver lining is that the clusters of dense data within an LLM are likely to be more computationally useful if they can be accessed individually, outside the one-size-fits-all context of the LLM. In fact, there appear to exist mathematical methods of separating these well-defined clusters from the high-dimensional space that they inhabit, transforming the curse of dimensionality into a ‘blessing of dimensionality’15.
Such mathematical methods are not yet sufficiently advanced to solve the current challenges of LLMs—but they do suggest a direction of travel. Specifically, they suggest an approach of locality.
Locality makes sense as an approach within the LLM feature space not least because it is how our minds make sense of the enormous dimensionality of the world we inhabit. Therefore it’s not only by analogy that locality should be our approach in the development of AI applications. As I recently wrote:
[R]esponsible AI … requires a detailed focus on local conditions. These local conditions include many features such as specific applications, types of users, training and inference data, AI models and other technical details, locations, and various other factors.
In practical terms, this indicates that the promising future of AI lies in domain-focused AI applications, in place of or in addition to one-size-fits-all, LLM-based foundation models like GPT-4.5, Claude or DeepSeek. Such focused applications might combine the impressive abilities of LLMs with other AI methods, such as neuro-symbolic methods. A combined approach aligns with recent ideas on compound AI systems16.
Continued AI innovation can also move us from the probabilistic/stochastic outputs of LLMs toward the reliable, deterministic outputs necessary for many real-world systems (especially in applications like critical infrastructure), as explored in the excellent recent essay On Probabilism and Determinism in AI. For example, there is a huge opportunity to build AI ‘agents’ that leverage AI to autonomously perform specific real-world actions, with the latest excitement around Chinese model Manus. Such agents will benefit in terms of reliability and safety from moving beyond the uncertain behavior of LLMs.17
For millennia, humanity has advanced by building a variety of purpose-fit tools (rather than by finding unified solutions that simultaneously address many of our needs), and there is good reason to believe that AI will take a similar path (despite current LLM and AGI hype). Even if we recognize that AI is a ‘general purpose technology’ with impact across sectors (like electricity or digital computers), it is still necessary to build specific tools and applications that use it.
In sum, there is every reason to be optimistic about a bright future of AI. However, in considering that future, we must be realistic about the real characteristics and limitations of AI systems, including the constraints of dimensionality that are explained in this blog, and the implications of those dimensionality constraints for LLMs. The promising way forward for AI, beyond LLMs, is one focusing on purpose-fit tools that use a variety of computational methods and focus on local conditions.
I have taken care with the technical detail, but errors are possible. Any corrections are welcome.
Tokens can also be used to represent non-word output like computer code or images. LLMs frequently deal with certain non-word data (e.g. images) by translating the data into embeddings, which are then converted into tokens.
LLMs typically include a parameter called ‘temperature’, which defines how likely it is that the LLM will choose the most likely response, vs. one with somewhat less likelihood. Higher temperature means more randomness, and ‘creativity’. However, even with temperature at the minimum, there can be ‘hallucinations’ (i.e. incorrect answers) and variance of responses between multiple trials with the same inputs.
The lead authors of this paper were Timnit Gebru (then of Google) and Emily Bender of the University of Washington. Gebru and co-author Margaret Mitchell lost their jobs leading Google’s AI ethics efforts in large part because of controversy over the paper. “Stochastic” in the title refers to the fact that LLMs incorporate randomness to ensure that their responses are not deterministic, including to provide an appropriate (and adjustable) level of ‘creativity’. “Parrots” is presumably self-explanatory.
The amazing capabilities of LLMs were built on decades of machine learning research. The leap in capabilities preceding ChatGPT was foreshadowed by the 2009 Google paper The Unreasonable Effectiveness of Data. Two more recent Google papers were key building blocks: Attention Is All You Need (2017, on the Transformer ‘attention’ mechanism underlying most current LLMs) and on BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (2018, BERT was one of the first LLMs).
Thanks to Dr Katharine Scarfe Beckett, who suggested this term in mid-2024.
These terms are mine. There may be better terms for these dimensionality concepts.
For various reasons, 1016 is probably a safe upper bound at least for the time being, but let’s give the data the benefit of the doubt.
LLM parameters are mathematical constructs, and most parameters appear not to be directly linked to specific characteristics of reality.
A factorial is an integer multiplied by each lesser integer down to 1 (or 2 if you prefer, the result is the same). So 5! is 5 x 4 x 3 x 2 x 1 = 120.
Even just 14 books have 10X more arrangements than there are living humans. Despite this apparent simplifying approach to everyone having a unique library, I don’t expect authors or bookstores to disappear soon.
That’s factorial notation, not an exclamation point as end-of-sentence punctuation.
This paper uses ‘latent space’ to mean what I refer to as ‘feature space’ (latent space usually refers to a simplified representation of the feature space), and ‘token space’ to refer to the portion of the feature space that is populated by through training on token-based data.
A few resources related to this vulnerability are Soft Prompt Threats: Attacking Safety Alignment and Unlearning in Open-Source LLMs through the Embedding Space (2024), Obfuscated Activations Bypass LLM Latent-Space Defenses (2024) and Latent Space: The New Attack Vector into Organizations (2024).
Gary Marcus and Ernest Davis suggested similar ideas in their 2019 book Rebooting AI. Unfortunately, Marcus has managed to distract attention from his very thoughtful and consistent analysis on these issues, through relentless criticism of a large number of leading figures in the AI community.
LLMs have supercharged development of agents, since LLMs allow agents to respond to a wide variety of real-world applications. But agents are not intrinsically linked to LLMs. Long before LLMs (and even before the recently flowering of AI since the early 2010s), we have had computer agents performing real-world tasks, with an increasing level of autonomy. Consider autonomous vehicles, which require deterministic behavior, and therefore cannot practically be governed by LLMs.